# JavaScript Event Loop
大家可能都知道JavaScript这门语言是单线程的语言吧,应该学过前端的都知道这个知识吧。单线程也就是说同一时间只能做一件事情。因为在JavaScript被设计出来的时候就是为了在浏览器上面运行,需要操作dom节点,如果是多个线程来操作dom节点的话,就会出现冲突的情况,如果需要解决冲突的话就要引入锁来实现,这样明显就变得很复杂了。JavaScript这门语言的设计者当成就是为了让它不那么复杂,所以就以单线程来设计它。
单线程就意味着所有任务需要排队,需要按步骤执行,前一步执行完了获取到了结果,后一步才会开始执行。这就是阻塞的
var i, t = Date.now()
for (i = 0; i < 100000000; i++) {}
console.log(Date.now() - t) // 238
像上面这样,如果排队是因为计算量大,CPU忙不过来,倒也算了
但是,如果是网络请求就不合适。因为一个网络请求的资源什么时候返回是不可预知的,这种情况再排队等待就不明智了。
所以为了利用多核CPU的计算能力,HTML5提出Web Worker标准,允许JavaScript脚本创建多个线程,但是子线程完全受主线程控制,且不得操作DOM。所以,这个新标准并没有改变JavaScript单线程的本质(只是引入了其他线程,协助JavaScript线程,完成需求)
# 现在引入两个概念:
# 【同步】
如果在函数返回的时候,调用者就能够得到预期结果(即拿到了预期的返回值或者看到了预期的效果),那么这个函数就是同步的,执行是阻塞的,需要上一步的得到结果之后才回去执行下一步。
Math.sqrt(2);//调用执行,立即返回结果
console.log('Hi');//调用执行,立即返回结果
# 【异步】
如果在函数返回的时候,调用者还不能够得到预期结果,而是需要在将来通过一定的手段(回调)得到,那么这个函数就是异步的。(引入异步的目的就是为了实现非阻塞)
fs.readFile('foo.txt', 'utf8', function(err, data) {
console.log(data);
});
在上面的代码中,我们希望通过fs.readFile函数读取文件foo.txt中的内容,并打印出来。但是在fs.readFile函数返回时,我们期望的结果并不会发生,而是要等到文件全部读取完成之后。如果文件很大的话可能要很长时间。所以,fs.readFile函数是异步的。正是由于JavaScript是单线程的,而异步容易实现非阻塞,所以在JavaScript中对于耗时的操作或者时间不确定的操作,使用异步就成了必然的选择。
异步的方法都是JavaScript之外的外部提供的方法,比如:
1、普通事件,如click、resize等
2、资源加载,如load、error等
3、定时器,包括setInterval、setTimeout等。
# 【异步详解】
一个异步过程包括两个要素:注册函数和回调函数,其中注册函数用来发起异步过程,回调函数用来处理结果(异步是为了实现非阻塞)
比如下面的代码,div.onclick这个函数就是注册函数,而箭头函数()=>{..}是回调函数,在代码放到浏览器中执行的时候,会依次执行所有的代码**onclick这个注册函数会和同步函数一样执行达到注册的功能**,后面的同步代码依然继续执行,并不会受到阻塞。然后当我们鼠标发起点击事件的时候,回调函数会在js主线程空闲的时候去执行。
div.onclick = () => {
console.log('click')
}
# 我们再引入两个概念:
# 【调用栈】
在了解调用栈之前我们先来了解下栈:
栈是临时存储空间,主要存储局部变量和函数调用。
基本类型数据(Number, Boolean, String, Null, Undefined, Symbol, BigInt)保存在在栈内存中。
引用类型数据保存在堆内存中,引用数据类型的变量是一个指向堆内存中实际对象的引用,存在栈中。
基本类型赋值,系统会为新的变量在栈内存中分配一个新值,这个很好理解。引用类型赋值,系统会为新的变量在栈内存中分配一个值,这个值仅仅是指向同一个对象的引用,和原对象指向的都是堆内存中的同一个对象。
对于函数,解释器创建了”调用栈“来记录函数的调用过程。每调用一个函数,解释器就可以把该函数添加进调用栈,解释器会为被添加进来的函数创建一个栈帧(用来保存函数的局部变量以及执行语句)并立即执行。如果正在执行的函数还调用了其他函数,新函数会继续被添加进入调用栈。函数执行完成,对应的栈帧立即被销毁。
栈虽然很轻量,在使用时创建,使用结束后销毁,但是不是可以无限增长的,被分配的调用栈空间被占满时,就会引起”栈溢出“的错误。
(function foo() {
foo()
})()
//很显然运行以上代码,会直接报错,栈溢出
为什么基本数据类型存储在栈中,引用数据类型存储在堆中?想继续了解js内存管理和v8的垃圾回收

function func1(){
cosole.log(1);
}
function func2(){
console.log(2);
func1();
console.log(3);
}
func2();
我们拿以上的全同步函数来举个栗子:
func2()入栈执行,
console.log(2)入栈执行,console.log(2)出栈,
func1()入栈执行,
console.log(1)入栈执行,console.log(1)出栈,
func1()出栈
console.log(3)入栈执行,console.log(3)出栈,
func2()出栈
# 【消息队列】
有些文章把消息队列称为任务队列,或者叫事件队列,总之是和异步任务相关的队列,可以确定的是,它是队列这种先入先出的数据结构,和排队是类似的,哪个异步操作完成的早,就排在前面。不论异步操作何时开始执行(这个执行是指注册函数执行),只要异步操作执行完成,就可以到消息队列中排队(这个消息就是指回调函数),这样,主线程在空闲的时候,就可以从消息队列中获取消息并执行(回调函数加入到消息队列,并执行)
# 【事件循环】
下面来详细介绍事件循环。下图中,主线程运行的时候,产生堆和栈,栈中的代码调用各种外部API(调用webAPI就是为了注册异步函数),异步操作执行完成后,就在消息队列中排队。只要栈中的同步代码执行完毕,主线程就会去读取消息队列,依次执行那些异步任务所对应的回调函数。(创建消息队列就是为了解决实现非阻塞)

从代码执行顺序的角度来看,程序最开始是按代码顺序执行代码的,遇到同步任务,立刻执行;遇到异步任务,则只是调用异步函数发起异步请求。此时,异步任务开始执行异步操作,执行完成后(回调函数)到消息队列中排队。程序按照代码顺序执行完毕后,查询消息队列中是否有等待的消息。如果有,则按照次序从消息队列中把消息放到执行栈中执行。执行完毕后,再从消息队列中获取消息,再执行,不断重复。
由于主线程不断的重复获得消息、执行消息、再取消息、再执行。所以,这种机制被称为事件循环
# 【宏任务与微任务】
以上机制在ES5的情况下够用了,但是ES6会有一些问题。我们来看一下下面这个Promise的例子:
console.log('script start')
setTimeout(function() {
console.log('timer over')
}, 0)
//Promise同样是用来处理异步的:
Promise.resolve().then(function() {
console.log('promise1')
}).then(function() {
console.log('promise2')
})
console.log('script end')
// script start
// script end
// promise1
// promise2
// timer over
如果按照刚才上面的消息队列调用的理解来说,应该是setTimeout中的timie over加入消息队列,然后是promise1、promise2依次加入消息队列等待执行。
但事实上并没有按照上面那样的顺序去执行。(创建promise后执行的异步任务完成返回的回调函数会被加入到微任务队列排队,同步任务执行完毕的时候会立即去执行微任务队列中的任务,然后再去执行消息队列中的任务。“优先级:同步任务>微任务队列>消息队列”)
微任务队列是直接放在执行上下文栈的栈底,当上下文中的同步执行完毕之后马上执行微任务队列,然后才去加入消息队列。
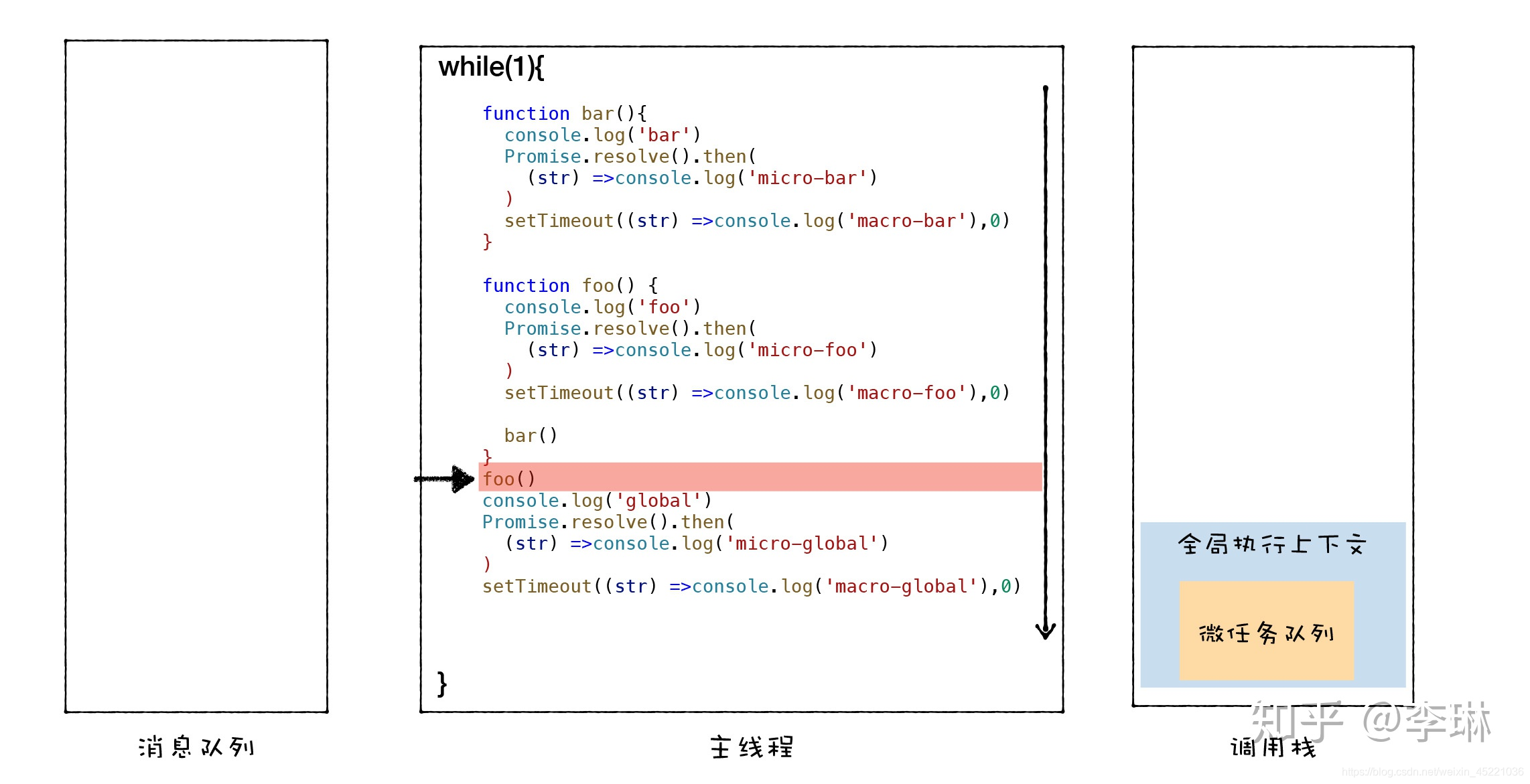
这里有两个新概念:macrotask(宏任务) 和 microtask(微任务)。
所有任务分为 macrotask 和 microtask:
macrotask:主代码块、setTimeout、setInterval等(可以看到,事件队列中的每一个事件都是一个macrotask,现在称之为宏任务队列)microtask:Promise、process.nextTick等
JS引擎线程首先执行主代码块。每次调用栈执行的代码就是一个宏任务,包括消息队列(宏任务队列)中的,因为执行栈中的宏任务执行完会去取消息队列(宏任务队列)中的任务加入执行栈中,即同样是事件循环的机制。
在执行宏任务时遇到Promise等,会创建微任务(.then()里面的回调),并加入到微任务队列队尾。
microtask必然是在某个宏任务执行的时候创建的,而在下一个宏任务开始之前,浏览器会对页面重新渲染(task >> 渲染 >> 下一个task(从任务队列中取一个))。同时,在上一个宏任务执行完成后,渲染页面之前,会执行当前微任务队列中的所有微任务。
也就是说,在某一个macrotask执行完后,在重新渲染与开始下一个宏任务之前,就会将在它执行期间产生的所有microtask都执行完毕(在渲染前)。
这样就可以解释 "promise 1" "promise 2"在 "timer over" 之前打印了。"promise 1" "promise 2"作为微任务加入到微任务队列中,而 "timer over"做为宏任务加入到宏任务队列(消息队列)中,它们同时在等待被执行,但是微任务队列中的所有微任务都会在开始下一个宏任务(消息队列)之前都被执行完。(也就是同步任务>微任务队列>消息队列,可以这么理解)
在node环境下,process.nextTick的优先级高于Promise,也就是说:在宏任务结束后会先执行微任务队列中的nextTickQueue,然后才会执行微任务中的Promise。
执行机制:
- 执行一个宏任务(栈中没有就从消息队列中获取)
- 执行过程中如果遇到创建微任务,就将它获取的结果回调函数的添加到微任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS引擎线程继续,开始下一个宏任务(从宏任务(消息)队列中获取)
# 总结
- JavaScript 是单线程语言,决定于它的设计最初是用来处理浏览器网页的交互。浏览器负责解释和执行 JavaScript 的线程只有一个(所有说是单线程),即JS引擎线程,但是浏览器同样提供其他线程,如:事件触发线程、定时器触发线程等。
- 异步一般是指:
- 网络请求
- 计时器
- DOM事件监听
- 事件循环机制:
- JS引擎线程会维护一个执行栈,同步代码会依次加入到执行栈中依次执行并出栈。
- JS引擎线程遇到异步函数,会将异步函数交给相应的Webapi,而继续执行后面的任务。
- Webapi会在条件满足的时候,将异步对应的回调加入到消息队列中,等待执行。
- 执行栈为空时,JS引擎线程会去取消息队列中的回调函数(如果有的话),并加入到执行栈中执行。
- 完成后出栈,执行栈再次为空,重复上面的操作,这就是事件循环(event loop)机制。