# 1】浏览器引擎
# 浏览器内核
就是指的:排版引擎(页面渲染引擎)。
- Gecko:早期网景、火狐使用。
- Trident:微软开发,IE4~11浏览器,但是Edge转向Blink。
- Webkit:苹果基于KHTML开发、开源。用于Safari、谷歌之前也使用。
- Blink:是Webkit的一个分支,Google开发,目前用于谷歌、Edge、Opera等。
# JavaScript引擎
职责:JS是高级语言------>汇编语言------->机器语言----->cpu执行
- SpiderMonkey
- Chakra
- JavaScriptCore:webkit
- V8:google
# 2】node版本管理
- nvm:官方提供
- n:TJ大神提,供交互式的版本管理(推荐)
# n
#安装最新的lts版本
n lts
#安装最新的current版本(支持更多语法)
n latest
#安装指定版本
n 12.18.1
# 3】REPL
REPL(Read-Eval-Print Loop)译为:“读取-求值-输出” 循环;
REPL是一个简单的、交互式的编程环境。(相当于浏览器的console控制台)
直接在终端输入:node回车进入。
# 全局对象区别:
浏览器中是有window、document等全局对象的,而node中则没有,而是有global、process等全局对象
# 4】node命令行传参
获取参数:process.argv
- argc:argument counter的缩写(传入的具体参数)
- argv:argument vector的缩写(传递参数的个数)
- vector 翻译过来是矢量的意思,在程序中表示一直数据结构。
- JS中是一种数组结构,里面存储一些参数信息。
//index.js
console.log(process.argv)
1、当我们直接 node index.js 回车执行
//打印出内容:
[
'/usr/local/bin/node',//node的全局绝对路径
'/Users/mac/Desktop/react_project/NodeRestudy/index.js'//index.js的绝对路径
]
2、当我们传递参数 node index.js env=production platform=ios author=rayhomie 回车执行
//打印出内容:
[
'/usr/local/bin/node',//node的全局绝对路径
'/Users/mac/Desktop/react_project/NodeRestudy/node命令行传参.js',//index.js的绝对路径
'env=production',//接收的参数
'platform=ios',//接收的参数
'author=rayhomie'//接收的参数
]
# 5】常见的全局对象
# 1、特殊全局对象
- 这些特殊全局对象实际上是模块中的变量,只是每个模块有,看起来像是全局变量
- 在命令行交互中不可以使用
- 包括:
__dirname、__filename、exports、module、require()
//index.js
console.log(__dirname)
console.log(__filename)
/*
/Users/mac/Desktop/react_project/NodeRestudy
/Users/mac/Desktop/react_project/NodeRestudy/特殊全局对象.js
*/
# 2、常见全局对象
- process对象:提供Node进程相关的信息
- 比如Node的运行环境、参数信息等
- 还可以将环境变量读取到process的env中
- console对象
- 定时器函数
setTimeout:在n毫秒后执行一次setInterval:每n毫秒重复执行一次setImmediate:I/O事件后的回调“立即”执行process.nextTick:添加到下一次tick队列中;
- global对象:所有东西都放在了global对象上(类似浏览器的window对象)
# 6】模块化
JavaScript被称之为披着C语言外衣的Lisp。(函数式编程)
但是早期JS还是存在很多缺陷:
- 比如var定义的变量作用域问题
- 比如JS的面向对象并不能像常规面向对象语言一样使用class
- 比如JS没有模块化
模块化规范:AMD、CMD、CommonJS(CJS)、ES Module(ESM)
- 规范都该包含的功能:模块本身可以导出暴露的属性,模块又可以导入自己需要的属性。
# CommonJS
- Node是CommonJS在服务器端一个具有代表性的实现
- Browserify是CommonJS在浏览器中的一种实现
- webpack打包工具内部对CommonJS的实现(还有各种模块规范实现)
Node中对CommonJS进行了实现和支持:
- 在Node中每一个js文件是都是一个单独的模块
- 在模块中CJS规范的核心变量:
exports、module.exports、requireexports和module.exports负责对模块中的内容进行导出。require函数可以导入其他模块(自定义模块,系统模块,第三方库模块)中的内容。
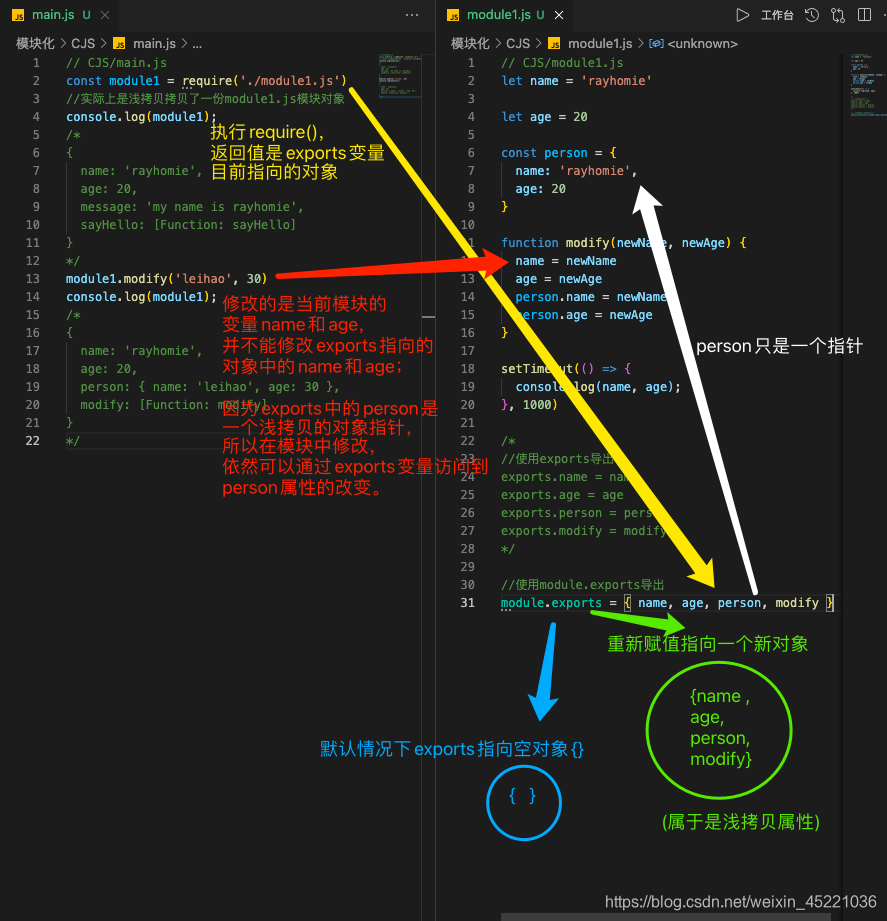
# 浅拷贝
//------------------- CJS/module1.js -------------
let name = 'rayhomie'
let age = 20
const person = {
name: 'rayhomie',
age: 20
}
function modify(newName, newAge) {
name = newName
age = newAge
person.name = newName
person.age = newAge
}
setTimeout(() => {
console.log(name, age);//leihao 30
}, 1000)
/*
//使用exports导出
exports.name = name
exports.age = age
exports.person = person
exports.modify = modify
*/
//使用module.exports导出
module.exports = { name, age, person, modify }
//----------------- CJS/main.js -----------------
const module1 = require('./module1.js')
//实际上是浅拷贝拷贝了一份module1.js模块对象
console.log(module1);
/*
{
name: 'rayhomie',
age: 20,
person: { name: 'rayhomie', age: 20 },
modify: [Function: modify]
}
*/
module1.modify('leihao', 30)
console.log(module1);
/*
{
name: 'rayhomie',
age: 20,
person: { name: 'leihao', age: 30 },
modify: [Function: modify]
}
*/
/*
//module1.js中的setTimeout打印:
leihao 30
*/
理解:默认情况下模块的exports变量指向一个空对象,require()执行返回的是exports变量指向的对象。我们导出的操作是exports.key=value或module.exports={...},这样对对象设置属性也就是:将要暴露的属性浅拷贝到exports指向的对象上。所以CJS是导出其实是浅拷贝模块。
# module.exports和exports有什么区别?
通过维基百科中对CommonJS的规范的解析:
- CJS中是没有module.exports的概念的
- 但是为了实现模块的导出,Node中使用的是Module的类,每一个模块都是Module的一个实例(
new Module()),也就是每一个文件都是一个module实例。 - 所以在Node中真正用于导出的其实不是exports,而是module.exports
- 其实直接使用exports导出,node内部也是通过module.exports来实现的。
因为源码里面做了一件事情:在当前模块最顶层执行module.exports=exports
//------------ CJS/module2.js -------------------
let name = 'rayhomie'
exports.name = name
console.log(exports, module.exports, exports === module.exports);
//{ name: 'rayhomie' } { name: 'rayhomie' } true
//------------- CJS/module3.js --------------------
let name = 'rayhomie'
module.exports ={ name }
console.log(exports, module.exports);
//{} { name: 'rayhomie' }
# require的查找规则
常见:require(X)
- 情况一:X是一个核心模块,比如path、http
- 直接返回核心模块,并停止查找
- 情况二:X是以
./或../或/(根目录)开头的- 将X当做一个文件在对应的本地目录下查找
- 如果有后缀名,按照后缀名的格式查找对应文件
- 如果没有后缀名,会按照以下顺序:
X、X.js、X.json、X.node的顺序查找
- 如果没有找到对应文件,则将X作为一个目录
- 查找该目录下的index文件:
X/index.js、X/index.json、X/index.node
- 查找该目录下的index文件:
- 如果还没有找到,那么就报错:not found
- 将X当做一个文件在对应的本地目录下查找
- 情况三:直接是一个X(没有路径),并且X不是一个核心模块
- 在当前文件夹下的node_modules文件夹下面查找
- 如果没有,则递归依次向上层查找,直到
/node_modules根目录下(全局依赖) - 如果还没有找到,那么报错:not found
# 模块加载过程
- 模块在被第一次引入时,模块中的js代码会被运行一次
- 模块多次引入时,会缓存,最终只加载(运行)一次
- Module实例上面有一个loaded属性,用于标记是否被加载过。
- 加载过程是深度优先算法DFS。
- 加载过程是同步的,会阻塞代码执行
# AMD
- Asynchronous Module Definition(异步模块定义)
- 它采用的是异步异步加载模块(加载的时候不影响后面代码的运行)
规范这是定义代码应该如何去编写,只有有了具体的实现才能被应用:
- AMD的实现比较常用的库是 require.js 和 curl.js
require.js的使用:
<!-- index.html -->
<script src="./lib/require.js" data-main="./index.js" ></script>
<!-- data-main属性定义项目脚本入口(等到src中的require.js加载完,立即去获取data-main中的文件并执行) -->
//------------ index.js --------------
//入口用于声明配置管理模块
(function () {
//require是外部require.js加载的全局变量
require.config({//需要配置
baseUrl: '',
paths: {//模块名与路径的映射(不加后缀名)
"module1": "./modules/module1",
"module2": "./modules/module2"
}
})
//加载module2.js中的代码
require(['module2'], function (module2) {
console.log(module2);
})
})()
//------------ ./modules/module1.js --------------
//每个模块需要使用define来定义
define(function () {
const name = 'rayhomie'
const age = 20
const sayHello = (name) => {
console.log('你好' + name)
}
return {//暴露给外部
name,
age,
sayHello
}
})
//------------ ./modules/module2.js --------------
//每个模块需要使用define来定义
define([
'module1'//依赖的模块
], function (module1) {//使用参数来接收导入的变量
console.log(module1.name)
console.log(module1.age)
module1.sayHello('leihao')
return {}
})
# CMD
- Common Module Definition(通用模块定义)
- 它采用了异步加载模块,吸取了Commonjs的写法简便的优点。
- (加载的时候不影响后面代码的运行)
- CMD规范的实现,比较常用的库是:Sea.js
<!-- index.html -->
<script src="./lib/sea.js"></script>
<script>
//直接使用脚本的主入口(区别于AMD,主入口中不需要配置管理各个模块)。
seajs.use('./index.js')
</script>
//------------ index.js --------------
define(function (require, exports, module) {
//和Commonjs规范差不多的导出导入
const { name, age, sayHello } = require('./modules/module1.js')
console.log(name);
console.log(age);
sayHello('leihao')
})
//------------ ./modules/module1.js --------------
define(function (require, exports, module) {
const name = 'rayhomie'
const age = 20
const sayHello = function (name) {
console.log('你好', name);
}
//和Commonjs规范差不多的导出导入
module.exports = { name, age, sayHello }
})
# ES Module
- 它使用了 import 和 export 关键字(并不是函数和对象,需要js引擎解析)
- 它采用了编译期的静态分析,并且也加入了动态引用的方式
- ESM由js引擎解析,在解析时已经确定了模块的依赖关系(在转换成AST之前),所以导入必须写在模块最前面。但ESM还提供了
import()的运行时环境。parse->ast->bytecode->runtime
- ESM将自动采用严格模式:
use strict
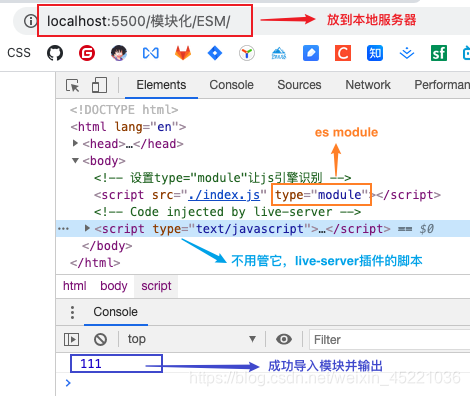
# 浏览器上使用
<!-- index.html -->
<!-- 设置type="module"让js引擎识别 -->
<script src="./index.js" type="module"></script>
//------------ index.js --------------
console.log(111)
报错问题:直接在浏览器打开index.html本地文件,会报跨域错误,由于浏览器的安全限制,不支持module以file的协议引入。解决办法是把index.html放在服务器上面,然后浏览器去请求。(VScode中可以安装Live Server插件,然后打开)

# 导出方式
- 方式一:导出变量
export const x
//------------ ./modules/module1.js --------------
export const name = 'rayhomie'
export const age = 20
export const sayHello = function (name) {
console.log('你好', name);
}
//------------ index.js --------------
//分别导入变量
import { name, age, sayHello } from './modules/module1.js';
//分别导入变量并起别名
import { name as Name, age as Age, sayHello as SayHello } from './modules/module1.js';
//分别导入全部变量放在一个对象中并起别名
import * as module1 from './modules/module1.js';
- 方式二:导出变量列表
export { x, y, z }
//------------ ./modules/module1.js --------------
const name = 'rayhomie'
const age = 20
const sayHello = function (name) {
console.log('你好', name);
}
export { name, age, sayHello }//导出的不是对象,只是语法(放置要导出的变量的引用列表)
//------------ index.js --------------
import { name, age, sayHello } from './modules/module1.js';
console.log(name, age);
sayHello('leihao')
- 方式三:给变量起别名
export { x as X, y as Y, z as Z }
//------------ ./modules/module1.js --------------
const name = 'rayhomie'
const age = 20
const sayHello = function (name) {
console.log('你好', name);
}
export { name as Name, age as Age, sayHello as SayHello}
//------------ index.js --------------
import { Name, Age, SayHello } from './modules/module1.js';
console.log(Name, Age);
SayHello('leihao')
- 方式四:默认导出(不需要变量名字)
export default { xxx, yyy, zzz }
//------------ ./modules/module1.js --------------
const name = 'rayhomie'
const age = 20
const sayHello = function (name) {
console.log('你好', name);
}
export default { name, age, sayHello }
//------------ index.js --------------
import module1 from './modules/module1.js';
const { name, age, sayHello } = module1
console.log(name, age);
sayHello('leihao')
- 方式五:导入+导出的语法
export { * as module1 } from './modules/module1.js'
一般用于封装库的时候,将所有接口放在一个文件中暴露
//------------ ./modules/module1.js --------------
const name = 'rayhomie'
const age = 20
const sayHello = function (name) {
console.log('你好', name);
}
export { name, age, sayHello }
//------------ index.js --------------
//先导入全部变量,再导出
export { * as module1 } from './modules/module1.js'
# import函数
parse->ast->bytecode->runtime
ESM由js引擎解析,在解析时已经确定了模块的依赖关系(在转换成AST之前),所以导入必须写在模块最前面。但ESM还提供了import()的运行时环境(异步加载)。(浏览器环境没有require()来加载模块,因为不支持CommonJS)
//------------ index.js --------------
let flag = true;
if (flag) {//运行时环境
const promise = import('./modules/module1.js')
//返回promise
promise.then((res) => {
console.log(res);
})
}
在webpack中使用ESM规范的import()会将该文件进行单独打包,用于动态加载。
# 打包工具和浏览器环境的ESM区别
webpack、rollup等模块化打包工具,只是实现了ESM规范,然后帮我们把代码解析转化模块化打包,打包出来的代码是常规浏览器都支持运行的代码(不需要浏览器再去解析一次,直接到浏览器运行代码即可)。需要跟浏览器环境的ESM做区别,浏览器环境的ESM代码是由JS引擎去解析并执行。
# 浏览器ESM加载过程
浏览器ESM加载js文件的过程是编译(解析)时加载的,并且是异步的。
import不能和运行时相关的内容放在一起使用:from后面的路径不能动态获取;不能建import放在条件语句中;
异步:体现在在script标签中设置了
type='module',那么这个srcipt脚本就是异步的就不会阻塞其他的脚本内容加载。相当于默认加了一个async属性。<!-- 设置type="module"让js引擎识别 --> <script src="./index.js" type="module"></script> <!-- 由于浏览器中ES module异步加载,所以不会阻塞后面的脚本执行(相当于默认加了一个async属性) --> <script src="./react.js"></script> <script>console.log('hello')</script>
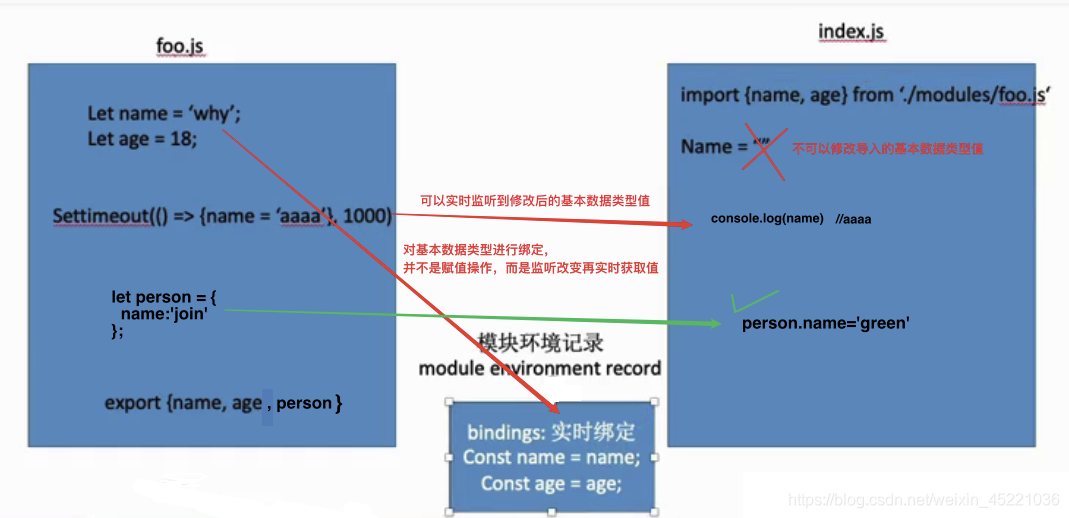
ESM通过export导出的是变量本身的引用(无论 基本 还是 引用 类型变量,都可以实时的获取到修改后的值,区别于CommonJS)
//------------ ./modules/module1.js -------------- let name = 'rayhomie' setTimeout(() => { name = 'leihao' }, 500) //CommonJS导出的是对象,所以基本类型就无法获取到变化之后的值。 export { name }//记住导出的不是对象,而是一种语法!!! //------------ index.js -------------- import { name } from './modules/module1.js'; console.log(name); setTimeout(() => { console.log(name); }, 1000) //结果:立即输出rayhomie,一秒后输出leihao。
ESM做了基本数据的实时绑定:(导入的基本数据类型值不能修改,但是引用数据类型可以修改它的属性)
# 在node中使用ESM
node的JS引擎也是本身有ES module的实现,但是默认是使用的CommonJS模块,我们需要以下操作,才可以让nodeJS引擎去解析ES module的模块代码。
- 在package.json中设置
type:module - 或者使用.mjs作为拓展名,node才会把他当成ES的模块。
# CJS和ESM交互
- 通常情况下,CommonJS不能加载ES module
- CJS是同步执行加载,但ESM必须经过静态分析,才可以执行。
- Node中不支持
- webpack等打包工具,可以支持。
- 多数情况下,ES module可以加载CommonJS
- ES module在加载CommonJS时,会将其
module.exports导出的内容作为export default导出方式来使用 - 这个依然要看具体的规范实现,比如webpack中是支持的,Node最新的Current版本也是支持的
- ES module在加载CommonJS时,会将其
//Node v16.1.0
//------------ ./modules/module.js --------------
const name = 'rayhomie'
const age = 20
module.exports = { name, age }//CommonJS导出
//------------ index.mjs --------------
import module2 from './modules/module2.js';//ES module导入
console.log(module2);//{ name: 'rayhomie', age: 20 }
# 7】常见内置模块
# path模块
# ①路径拼接
path.resolvepath.join
区别:resolve会判断我们拼接的路径字符串第一个参数中,是否有以/或./或../开头的路径
/:如果以/开头则直接拼接无/或./:如果是以./开头,则是从电脑根路径开始cd拼接(没有/也会被当成./,比如:'user/mac'等价于'./user/mac')../:如果以../开头也是从电脑根路径开始cd拼接,但是需要cd到上一层目录
//记住下面的这三个拼接是一样的:
path.resolve(__dirname,'index.js')// /Users/mac/index.js
path.join(__dirname,'index.js')// /Users/mac/index.js
path.join(__dirname,'/index.js')// /Users/mac/index.js
//但是下面这个不一样:
path.resolve(__dirname,'/index.js')// /index.js
写一个resolve方法:
const resolve = dir => path.resolve(__dirname, dir)
console.log(resolve('src'));///Users/mac/src
//webpack中就使用这样的方式起别名:
{
alias:{
"@":resolve("src"),
"components":resolve("src/components")
}
}
# ②获取路径信息
path.dirname:文件夹路径path.basename:文件名path.extname:后缀名
# fs模块
①同步操作②异步回调③异步promises
const fs = require('fs')
const filePath = './text.txt'
//同步操作
const syncFile = fs.readFileSync(filePath)
console.log(syncFile);
//异步回调
fs.readFile(filePath, (err, data) => {
if (err) {
console.log(err);
return;
}
console.log('读取的内容是:', data)//默认是读取到十六进制的buffer类型
console.log(data.toString())//Buffer转成String类型
})
//使用promises
const promisesFile = fs.promises.readFile(filePath)
promisesFile.then(data => console.log(data))
# events模块
# 基本使用
const EventEmitter = require('events')
//1.创建发射器实例
const emitter = new EventEmitter()
//2.监听某个事件
//on是addListener的简写
emitter.on('eventname', (...args) => {
console.log('监听到了eventname事件第1次', ...args);
})
emitter.addListener('eventname', (...args) => {
console.log('监听到了eventname事件第2次', ...args);
})
//3.触发事件
emitter.emit('eventname','rayhomie','leihao')
/*
打印结果:
监听到了eventname事件第1次 rayhomie leihao
监听到了eventname事件第2次 rayhomie leihao
*/
# 不常用
const EventEmitter = require('events')
const emitter = new EventEmitter()
emitter.on('tap', (...args) => {
console.log('监听到了tap', ...args);
})
emitter.on('click', (...args) => {
console.log('监听到了click', ...args);
})
console.log(emitter.eventNames());// [ 'tap', 'click' ]
console.log(emitter.listenerCount('tap'));// 1
console.log(emitter.listeners('click'));// [ [Function (anonymous)] ]
# 8】Npm包管理
# package.json
必填写的属性:name、version
name是项目的名称
version是的当前项目的版本号
private记录当前的项目是否私有
description是描述信息
author是作者相关信息
license是开源协议
main属性(在webpack中这个mian字段没有用,因为入口交给webpack去打包了,而且这个main定义的入口只遵循CommonJS规范,不支持tree-shaking)
//别人使用我们的包时,require时就会到node_modules下的包里面找main入口文件去加载。 const rayhomieui=require('rayhomieui')module属性不是npm官方的字段(webpack和rollup联合推出),定义了ES module规范的入口(方便tree-shaking)
types属性是定义类型声明文件入口
browserslist属性:用于配置打包后的JavaScript浏览器的兼容情况,否则我们需要配置polyfills来支持语法。
# 依赖版本号
semver版本规范X.Y.Z:
- X主版本号(major):兼容不了以前的版本。
- Y次版本号(minor):向下兼容,加了新功能特性。
- Z修订号(patch):没有新功能,只是修复之前版本的bug。
^x.y.z:表示x保持不变的,y和z永远安装最新版本。
~x.y.z:表示x和y保持不变的,z永远安装最新版本。
# npm install原理
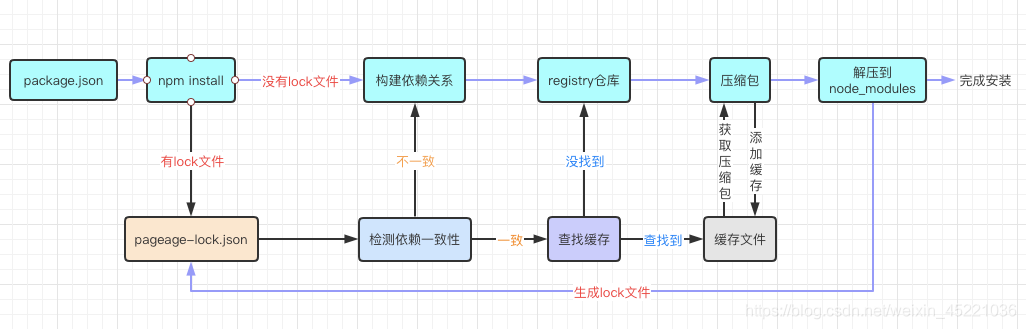
查看npm缓存
#获取当前的缓存文件夹
npm config get cache
# yarn工具
弥补npm早期的缺陷,npm5改进升级了很多。
npm i yarn -g全局安装yarn。
# npx
npx是npm5.2之后自带的一个工具
作用:常用用它来调用项目中的某个模块的命令。
举例:比如我们全局安装webpack@5.37.0,项目中安装webpack@3.6.0。此时我们在项目中使用命令webpack --version,使用的是全局的5.37.0。此时我们想要使用项目中的局部命令,①只能通过./node_modules/.bin/webpack --version来使用局部webpack,②在package.json中设置脚本也是使用的局部的命令,③也可通过npx webpack --version来调用局部命令。
# 9】手写脚手架
# 命令行编写
需要使用到Linux中的**shebang(hashbang)**符号#!,作用是根据环境来执行脚本。
下面这个就是在index.js文件中写了一句shebang代码,表示的是别人在运行这个脚本的时候,需要根据环境去找node可执行文件,然后找到node之后去执行index.js后面的代码内容。
#!/usr/bin/env node
console.log('hello world')
# 配置bin字段
在package.json中有一个bin字段,可以对当前包的终端命令行进行配置:
{
"name": "lh",
"version": "1.0.0",
"description": "",
"main": "index.js",
"bin": {//配置命令行
"lh": "index.js"//当别人安装我们的包之后,可以指向lh命令。然后就去运行index.js
},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "rayhomie <1572801584@qq.com>",
"license": "MIT"
}
流程:但别人安装了我们的包之后可以使用我们在bin中定义的lh命令,去执行index.js文件,而且会根据文件中的shebang指令去当前环境找node,器执行文件中的脚本。
# 开发时link测试
我们在开发时,可以在当前包下使用npm link命令。将包链接到当前环境,然后就可以模拟用户安装了我们的包的操作,再使用我们的包了。软链接后的包可以在全局包中目录下查看npm root -g,正式发包后可以把它删除了。
此时在终端命令行使用lh命令,即可看到终端输出hello world。
# 命令参数传递
例子,写一个lh --version查看版本号的命令。
#!/usr/bin/env node
//参数-v,--version获取版本号
process.argv.find(item => ['--version', '-V'].includes(item))
&& console.log(require('./package.json').version);
这样通过process.argv来获取参数判断显然很麻烦,所以我们可以使用一个commander库进行命令行开发更方便。
#!/usr/bin/env node
const program = require('commander')
program.version(require('./package.json').version)
program.parse(process.argv)//解析参数,--help
此时在终端输入lh --help可以解析出所有的参数。lh --version就可以显示当前版本号。
# commander
#!/usr/bin/env node
const program = require('commander')
//查看版本号
program.version(require('./package.json').version)
//添加自己的options
program.option('-h --lh', 'a lh cli')
//手动设置路径,<>为可选参数
program.option('-d --dest <dest>', 'a destination folder, example: -d /src/components')
//监听参数传递
program.on('--help', function () {
console.log('监听到--help!!!');
})
//解析一定要写在参数配置的后面
program.parse(process.argv)
/*
//在program.parse后面可以获取到参数信息
const opts = program.opts()
//lh -h,打印:true
console.log(opts.lh);
//lh -d /src/components,打印:/src/components
console.log(opts.dest);
*/
//命令
program
.command('create <project> [others...]')//创建命令
.description('clone repository into a folder')//描述
.action((project, others) => {//可以获取参数
console.log(project, others);
})//触发
# download-git-repo
使用这个库可以用node克隆git的仓库到本地。
# promisify
在node中可以使用node提供的工具,将回调形式转成promise
const { promisify } = require('util')
const download = promisify(require('download-git-repo'))
download(...).then(res=>{ }).catch(err=>{ })
# node执行终端命令
需要用到child_process模块(封装terminal.js)
//进程通信
const { exec, spawn } = require('child_process')
const commandSpawn = (...args) => {
return new Promise((resolve, reject) => {
//创建子进程,执行终端命令,并返回子进程,获取子进程信息
const childProcess = spawn(...args)//返回值是该子进程(进行进程间通信)
childProcess.stdout.pipe(process.stdout)//将子进程的输出流导入到当前进程的输出流中
childProcess.stderr.pipe(process.stderr)//错误信息导入
childProcess.on('close', () => {
resolve()
})//监听关闭
})
}
const commandExec = (...args) => {
return new Promise((resolve, reject) => {
const childProcess = exec(...args)
childProcess.stdout.pipe(process.stdout)
childProcess.stderr.pipe(process.stderr)
childProcess.on('close', () => {
resolve()
})
})
}
module.exports = {
commandSpawn,
commandExec
}
进行调用执行终端命令。具体exec和spawn的参数可以在官网查看。
commandSpawn(npm, ['install', '--force'], { cwd: `./${project}` })//cwd选择执行路径
# 使用node修改文件内容
这里就举个栗子,修改packge.json中的name字段
const path = require('path')
//使用promisify包裹
const { promisify } = require('util')
const readFile = promisify(require('fs').readFile)
const writeFile = promisify(require('fs').writeFile)
async function writeProjectName(Path, name) {//修改package.json的name(传入的参数是项目根路径,name字段需要更改的名字)
//读取文件
const data = await readFile(path.join(Path, 'package.json'), 'utf8')
const newList = {}//暂存新对象
const list = JSON.parse(data)
for (let key in list) {
if (key === 'name') {
newList[key] = name
continue
}
newList[key] = list[key];
}
let newContent = JSON.stringify(newList, null, 2);
//重写文件
await writeFile(path.join(Path, 'package.json'), newContent, 'utf8')
}
module.exports = writeProjectName
# 10】Buffer
计算机中所有的内容最终都会使用二进制来表示,如文字、数字、图片、音频、视频等。
js中0x开头的都是16进制数。
使用常用场景:
- 在node使用buffer对二进制数据进行处理。Node中可以使用sharp库,就是读取图片或者传入图片的Buffer对其再进行处理。
- 一个保存文本的文件并不是使用utf-8进行编码的,而是使用GBK,那么我们必须读取到他们的二进制数据,再通过GBK转换成对应的文字。
- Node中通过TCP建立长连接,TCP传输的是字节流,我们需要将数据转成字节再进行传入,并且需要知道传输字节的大小(客户端需要根据大小来判断读取多少内容)
//推荐使用Buffer.from,而不是new Buffer
const message = '你好啊'
//1.对中文使用buffer进行utf8的编码
let utf8buffer = Buffer.from(message, 'utf8')
console.log(utf8buffer);// <Buffer e4 bd a0 e5 a5 bd e5 95 8a>
//2.toString默认对utf8解码
console.log(utf8buffer.toString());// 你好啊
console.log(utf8buffer.toString('utf16le'))// 뷤붥闥
//1.对中文使用buffer进行utf16le的编码
let utf16lebuffer = Buffer.from(message, 'utf16le')
console.log(utf16lebuffer);// <Buffer 60 4f 7d 59 4a 55>
//2.toString对utf16le解码
console.log(utf16lebuffer.toString('utf16le'));// 你好啊
# buffer的创建方式
# new Buffer
Deprecated: Use Buffer.from(string[, encoding])instead.
被重声明,请使用Buffer.from
# Buffer.from
//Buffer.from(string[, encoding])
const buf1 = Buffer.from('buffer');
const buf2 = Buffer.from(buf1);
buf1[0] = 0x61;
console.log(buf1.toString());
// Prints: auffer
console.log(buf2.toString());
// Prints: buffer
# Buffer.alloc
//Buffer.alloc(size[,fill[,encoding]])
let buffer = Buffer.alloc(8)//给当前buffer分配8个字节内存
console.log(buffer);// <Buffer 00 00 00 00 00 00 00 00>
//直接修改buffer内容
buffer[0] = 88// 十进制的88
buffer[1] = 0x88// 十六进制的88
console.log(buffer);// <Buffer 58 88 00 00 00 00 00 00>
let fillbuffer= Buffer.alloc(8,'12')// 分配8字节并填充满字符串
console.log(fillbuffer);// <Buffer 31 32 31 32 31 32 31 32>
console.log(fillbuffer.toString());// 12121212
# Buffer和文件操作
读取文件的本质都是读取二进制数据
//文本文件处理
const fs = require('fs')
fs.readFile('./text.txt', { encoding: 'utf8' }, (err, data) => {
console.log(data);// 雷浩
})
fs.readFile('./text.txt', (err, data) => {
console.log(data);// <Buffer e9 9b b7 e6 b5 a9>
console.log(data.toString());// 雷浩
})
# 使用sharp处理图片文件
(它内部也是需要拿到buffer数据来处理图片)
//处理图片文件
const fs = require('fs')
//使用sharp库来处理图片数据https://github.com/lovell/sharp#documentation
const sharp = require('sharp');
//方式一:传入buffer
fs.readFile('./picture.jpg', (err, data) => {
sharp(data)
.resize(20, 20)
.toFile('./20x20.jpg')
})
//方式二:传入路径
sharp('./picture.jpg')
.resize(100, 100)
.toFile('./100x100.jpg')
# 11】事件循环和异步IO
# 事件循环
- 事实上我们把事件循环理解成我们编写的JavaScript和浏览器或者Node之间的一个桥梁。
- 浏览器事件循环是一个我们编写的JavaScript代码和浏览器Api调用(setTimeout/AJAX/监听事件等)的一个桥梁,桥梁之间他们通过回调函数进行沟通。
- Node的事件循环是一个我们编写的JavaScript代码和系统调用(fs、network)之间的一个桥梁,桥梁之间他们通过回调函数进行沟通。
# 进程和线程
- 进程(process):计算机已经运行的应用程序;
- 线程(thread):操作系统中能够运行运算调度的最小单位;
- 进程可以看成线程的容器。
# 浏览器事件循环
宏任务:同步代码、timer回调、浏览器事件回调、ajax回调、DOM监听、UI Rendering
微任务:Promise的then回调、Mutation Observer API、queueMicrotask()等
宏任务执行结束完成后立即去清空微任务队列,直到微任务被清空才去执行下一轮宏任务。(只维护两个队列:消息队列和微任务队列)
- 在执行任何一个宏任务之前(不是列队,是一个宏任务),都会先去查看微任务队列中是否有任务需要执行
- 也就是宏任务执行之前,必须保证微任务队列是空的
- 如果不为空,那么就优先执行微任务队列中的任务(回调)
<script>
console.log('开始')
setTimeout(() => {
console.log('结束')
}, 0)
new Promise((resolve, reject) => {
resolve('then')
}).then(res => console.log(res))
for (let i = 0; i < 1000000000; i++) {
}
//顺序:开始----------->then-->结束
//等待若干秒后才执行结束。因为timer的回调需要等待宏任务结束才执行
//浏览器事件、ajax等和timer一样都是异步宏任务,会被加到宏任务队列
</script>
# 题目一:
setTimeout(() => {
console.log('set1');
new Promise((resolve) => {
resolve()
}).then(() => {
new Promise((resolve) => {
resolve()
}).then(() => {
console.log('then4');
})
console.log('then2');
})
})
new Promise((resolve) => {
console.log('pr1');
resolve()
}).then(() => {
console.log('then1');
})
setTimeout(() => {
console.log('set2');
})
console.log(2);
queueMicrotask(() => {
console.log('queueMicrotask1');
})
new Promise((resolve) => {
resolve()
}).then(() => {
console.log('then3');
})
//答案:
/*
pr1
2
then1
queueMicrotask1
then3
set1
then2
then4
set2
*/
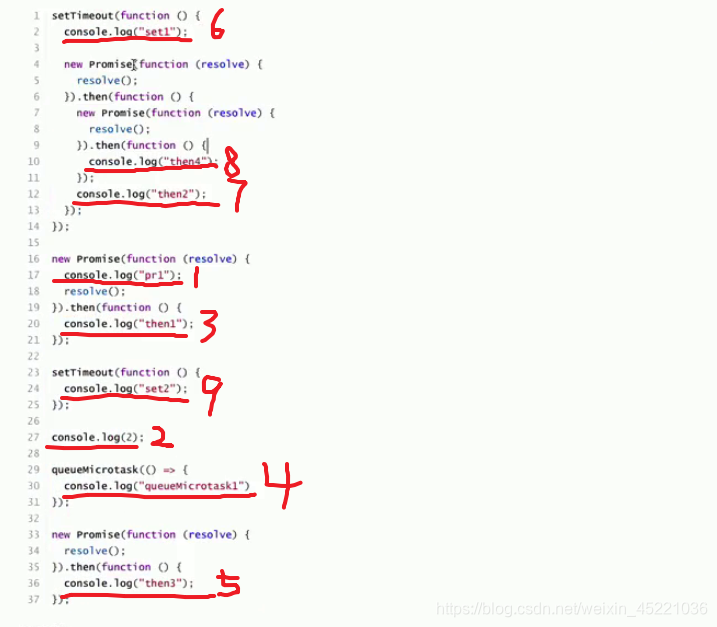
# 题目二:
async function async1() {
console.log('async1 start');
await async2();
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(() => {
console.log('setTimeout')
}, 0)
async1()
new Promise((resolve) => {
console.log('promise1');
resolve()
}).then(() => {
console.log('promise2');
})
console.log('script end');
//答案:
/*
script start
async1 start
async2
promise1
script end
async1 end
promise2
setTimeout
*/

await async2()可以看做成new Promise(resolve=>{ async2() .. })
await下面的代码就是认为是then回调函数中的代码
# 题目三:
被resolve之后才会调用一次.then。(连续的.then调用是一次一次加入微任务中的)
Promise.resolve().then(()=>{
console.log(1)
Promise.resolve().then(()=>{
console.log(3)
})
}).then(()=>{
console.log(2)
})
/*
1
3
2
*/

# 题目四:
Promise.resolve().then(()=>{
console.log(0)
setTimeout(()=>{
console.log('宏任务')
},0)
return Promise.resolve(4)
}).then((res)=>{
console.log(res)
})
Promise.resolve().then(()=>{
console.log(1)
}).then(()=>{
console.log(2)
}).then(()=>{
console.log(3)
}).then(()=>{
console.log(5)
}).then(()=>{
console.log(6)
})
/*
0
1
2
3
4
5
6
宏任务
*/
讲道理,按照我们对事件循环的知识体系去解答,得到的答案应该是这样的:0,1,4,2,3,5,6,宏任务。但是在node环境和浏览器环境运行却答案不一致。
这道题答不对没关系,这题属于是顶级牛角尖的题目(与Promise实现有关)
顶级解释在这里:求前端大佬解析这道Promise题,为啥resolved 是在 promise2之后输出?
# Node事件循环
# node架构分析
浏览器中的EventLoop是根据HTML5规范来实现的,不同的浏览器可能会有不同的实现,而Node中是由libuv实现的。
- libuv中主要维护了一个EventLoop和worker threads(线程池),libuv是一个多平台的专注于异步IO的库。libuv采用的是非阻塞异步IO的调用方式
- Event Loop负责调用系统的一些其他操作:文件的IO、Network、child-process等
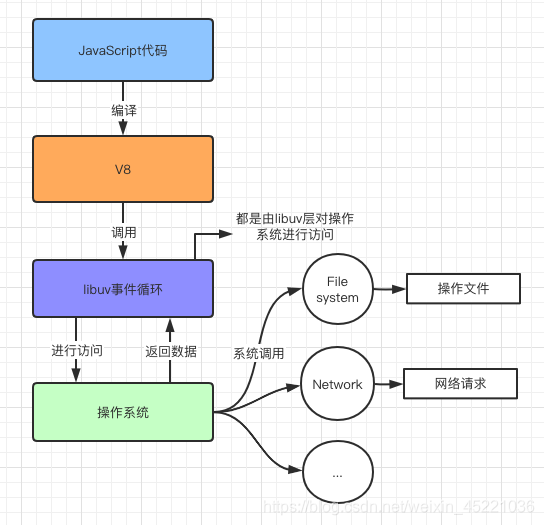
# 阻塞IO和非阻塞IO
操作系统通常提供了两种调用方式:阻塞式调用和非阻塞式调用
- 阻塞式调用:调用结果返回之前,当前线程处于阻塞态(阻塞态CPU是不会分配时间片的)调用线程只有在得到调用结果之后才会继续执行
- 非阻塞式调用:调用执行之后,当前线程不会停止执行,只需要过一段时间来检查一下有没有结果返回即可(轮询操作:需要知道是否系统调用完成)
开发中的很多耗时操作都是基于非阻塞式调用:
- 网络请求本身使用了Socket通信,而Socket本身提供了select模型,可以进行非阻塞式的工作
- 文件读写的IO操作,我们可以使用操作系统提供的基于事件的回调机制
如果主线程频繁的去进行轮询的工作,那么必然会大大降低性能,并且开发中我们不只是一个文件的读写,可能是多个文件,而且可能是多个功能的系统非阻塞式调用,如:网络IO、数据库IO、子进程调用等。所以libuv提供了一个线程池(thread pool):
- 线程池会负责所有相关的操作,并且会通过轮询或者其他的方式等待结果
- 当获取到结果时,就可以将对应的回调函数放到事件循环中(某一个事件队列)
- 事件循环就可以负责接管后续的回调工作,告知JavaScript应用程序执行对应的回调函数
# 阻塞和非阻塞,同步和异步的区别?
阻塞和非阻塞是对于被调用者来说的
- 这里就是系统调用,操作系统为我们提供了阻塞调用和非阻塞调用
同步和异步是对于调用者来说的
- 我们在程序中发起调用之后,不会进行其他任何的操作,只是等待结果,这个过程就称之为同步调用
- 发起调用之后,并不会等待结果,继续完成其他的工作,等到有回调时再去执行,这个过程就是异步调用
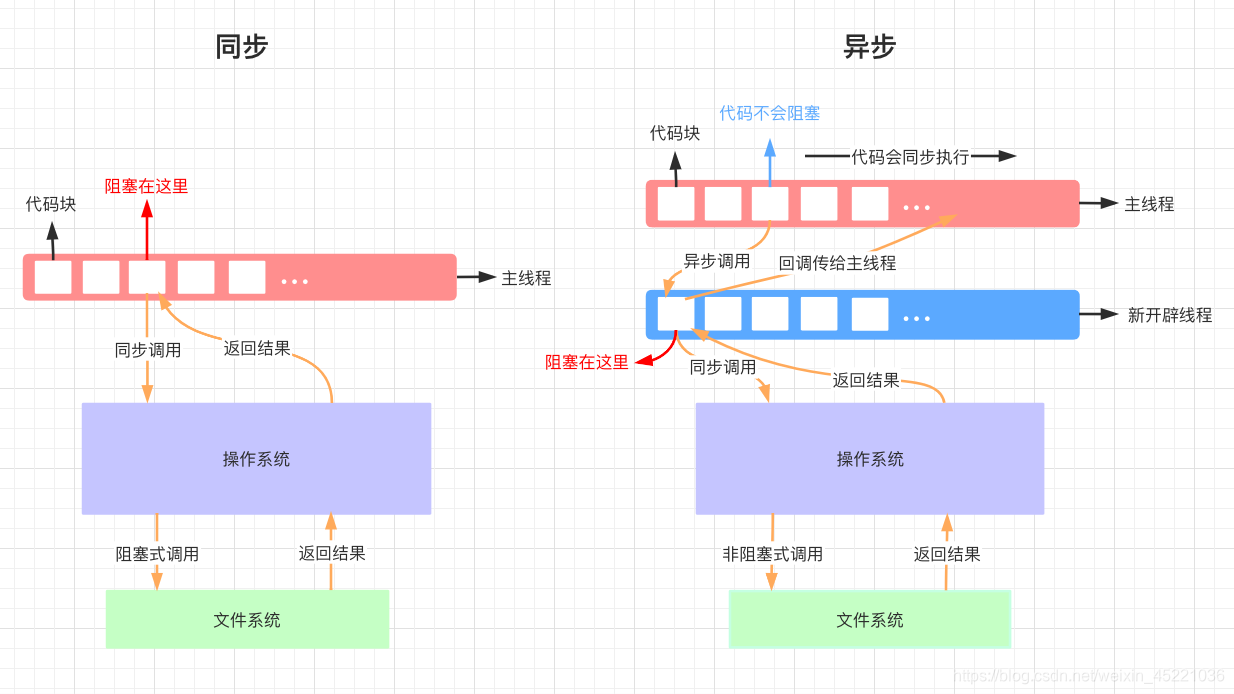
# node事件循环阶段
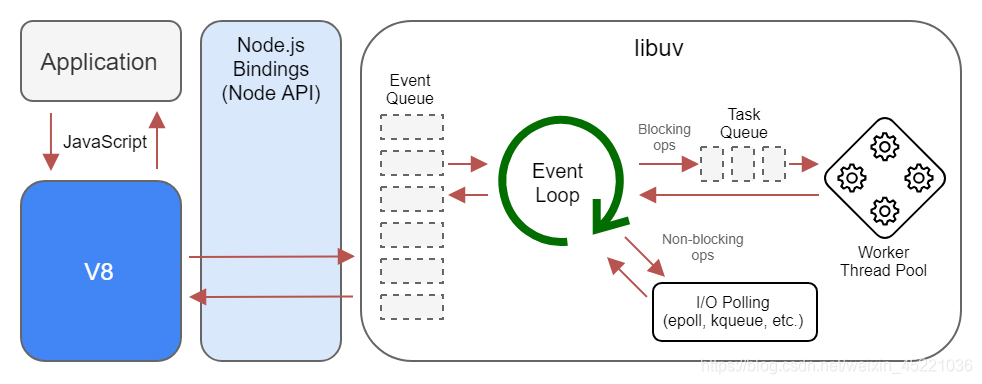
无论是我们的文件IO、数据库、网络IO、定时器、子进程,在完成对应的操作后,都会将对应的结果和回调函数放到事件循环(任务队列)中,事件循环会不断地从任务队列中取出对应的事件(回调函数)来执行。
Node中一次完整的事件循环Tick分成很多个阶段:(也就是我们注册调度任务(交给Node完成一些IO事件),Node处理完成之后,将结果以回调函数的形式返回给我们,这些回调函数按照事件循环的顺序来执行)
- 定时器(Timers):本阶段执行已经被
setTimeout()和setInterval()的调度回调函数 - 待定回调(Pending Callback):对某些系统操作(如TCP错误类型)执行回调,比如TCP连接时接收到ECONNREFUSED
- Idle、prepare:仅系统内部使用
- 轮询(Poll):检索新的I/O事件;执行与I/O相关的回调;(停留时间最长,希望IO的回调尽早响应)
- 检测:
setImmediate()的回调函数在这里执行 - 关闭的回调函数:一些关闭的回调函数,如:
socket.on('close',...)
# 宏任务微任务
Node宏任务:setTimeout、setInterval、IO事件、setImmediate、close事件;
Node微任务:Promise的then回调、queueMicrotask、process.nextTick
注意:process.nextTick是放在单独的一个队列里面存放(不和Promise.then、queueMicrotask放在一起)
# Node事件循环维护的队列
微任务队列:next ticks队列、其他微任务队列(promise.then、queueMicrotask)
宏任务队列:timers队列(setTimeout、setInterval)、轮询队列(io事件)、check队列(setImmediate)、close队列(close回调)
# 题目一:
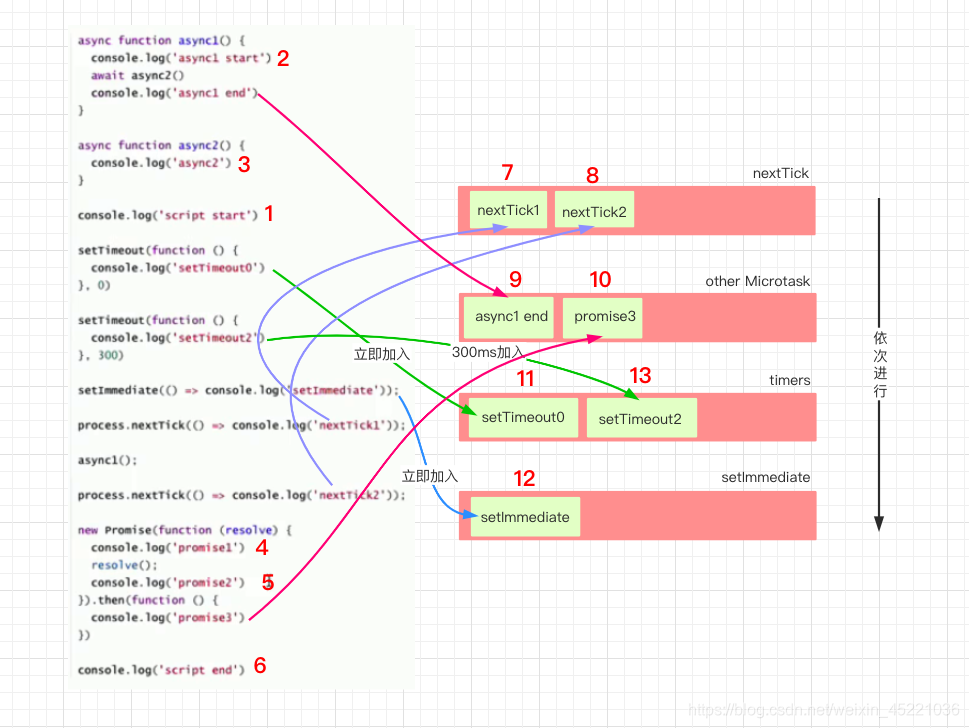
async function async1() {
console.log('async1 start');
await async2()
console.log('async1 end');
}
async function async2() {
console.log('async2');
}
console.log('script start');
setTimeout(() => {
console.log('setTimeout0');
}, 0)
setTimeout(() => {
console.log('setTimeout2');
}, 300)
setImmediate(() => console.log('setImmediate'))
process.nextTick(() => console.log('nextTick1'))
async1()
process.nextTick(() => console.log('nextTick2'))
new Promise((resolve) => {
console.log('promise1');
resolve();
console.log('promise2');//会被同步执行
}).then(() => {
console.log('promise3');
})
console.log('script end');
//答案:
/*
script start
async1 start
async2
promise1
promise2
script end
nextTick1
nextTick2
async1 end
promise3
setTimeout0
setImmediate
setTimeout2
*/
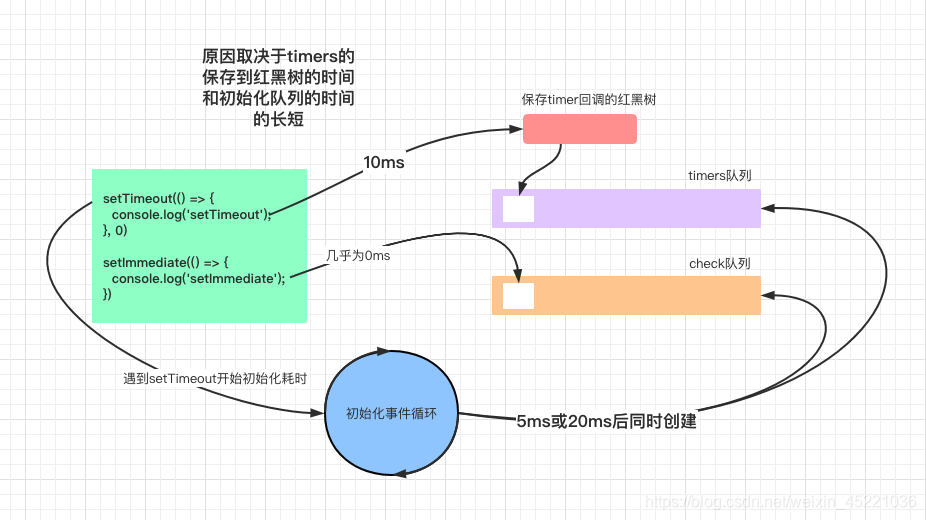
# 题目二:
setTimeout(() => {
console.log('setTimeout');
}, 0)
setImmediate(()=>{
console.log('setImmediate');
})
//答案:
/*
setTimeout
setImmediate
或者
setImmediate
setTimeout
*/
原因:初始化事件循环队列需要时间,timers的回调先保存到红黑树再放到timers队列中也需要时间,setImmediate的回调不需要保存直接加入到check队列几乎不耗时。
# 12】Stream
Node中很多对象是基于流实现的:
- http模块的Request和Response对象
- process.stdout对象
另外:官网说所有的流都是EventEmitter的实例
Nodejs中有四种基本流类型:
- Writable:可以向其写入数据的流(
fs.createReadStream) - Readable:可以从中读取数据的流(
fs.createWriteStream) - Duplex:同时为Readable和Writable的流
- Transform:Duplex可以在写入和读取数据时修改或转换数据的流
# Readable流的使用
const fs = require('fs')
//流的方式读取
const reader = fs.createReadStream('./read.txt', {
code: 'utf8',
highWaterMark: 2//每次最多读两个字节
})
//监听data回调获取读取的数据
reader.on('data', (data) => {
console.log(data.toString());
reader.pause()//暂停读取
setTimeout(() => {
reader.resume()//恢复读取
}, 1000)
})
//监听文件被打开
reader.on('open', () => {
console.log('文件被打开');
})
//监听文件关闭
reader.on('close', () => {
console.log('文件被关闭');
})
# Writable流的使用
const fs = require('fs')
const writer = fs.createWriteStream('./write.txt')
writer.write('你好啊', (err) => {
if (err) {
console.log(err);
return
}
console.log('写入成功一次');
})
writer.write('雷浩',(err)=>{
console.log('写入成功二次');
})
// writer.close()//可以使用close
writer.end('End')//也可以使用end(传入参数可以写入到文件中)
//监听关闭
writer.on('close', () => {
console.log('文件已关闭');
})
# pipe方法的使用
const fs = require('fs')
const writer = fs.createWriteStream('./write.txt')
const reader = fs.createReadStream('./read.txt', {
code: 'utf8',
highWaterMark: 2//每次最多读两个字节
})
reader.pipe(writer)//将读到的值,导入输出流
writer.close()
# 13】Http
web服务器:当客户端需要某一个资源时,可以向一台服务器,通过Http请求获取到这个资源;提供资源的这个服务器,就是web服务器。
# 创建web服务器
const http = require("http");
//创建一个web服务器
const server = http.createServer((req, res) => {
res.end("hello server");
});
//启动服务器
server.listen(3000, () => {
console.log(`~服务器已经启动在3000端口~`);
});
由于原生http较为复杂:url判断、method判断、参数处理、逻辑代码处理等,所以我们需要框架进行处理。
# 14】Express
Express整个框架的核心就是中间件,理解了中间件其他都很简单,其实中间件就是一个回调函数。
# 使用方式:
方式一:通过express-generator脚手架创建
#安装
npm i -g express-generator
#创建脚手架模板
express demo_name
方式二:从零自己搭建
const express = require("express");
//express其实是一个函数:createApplication => 返回app对象
const app = express();
//监听默认路径
app.get("/", (req, res, next) => {
res.end("hello get express");
});
app.post("/", (req, res, next) => {
res.end("hello post express");
});
//开启监听
app.listen(8888, () => {
console.log("express服务器启动成功");
});
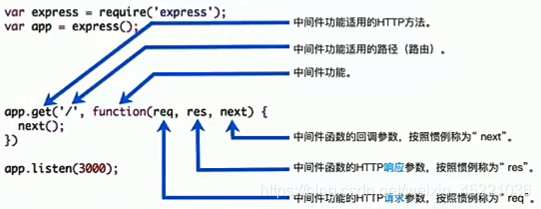
express是一个路由和中间件的web框架,它本身的功能非常少,Express应用程序的本质上是一系列中间件函数的调用。
中间件:本质上是传递给express的一个回调函数。
- 这个回调函数接收三个参数:
- 请求对象(request对象)
- 响应对象(response对象)
- next函数(在express中定义的用于执行下一个中间件的函数)
- 如果当前中间件功能没有结束请求-响应周期,则必须调用
next(),将控制权传递给下一个中间件功能,否则请求将被挂起。
以路由中间件为例: